Research Topics
Our research group is dedicated to the algorithmic, theoretical, and applied investigation of frontier topics in artificial intelligence, with a focus on trustworthy AI, large language models, and federated learning
Topic 1: Trustworthy Multimodality (Multi-view) Learning
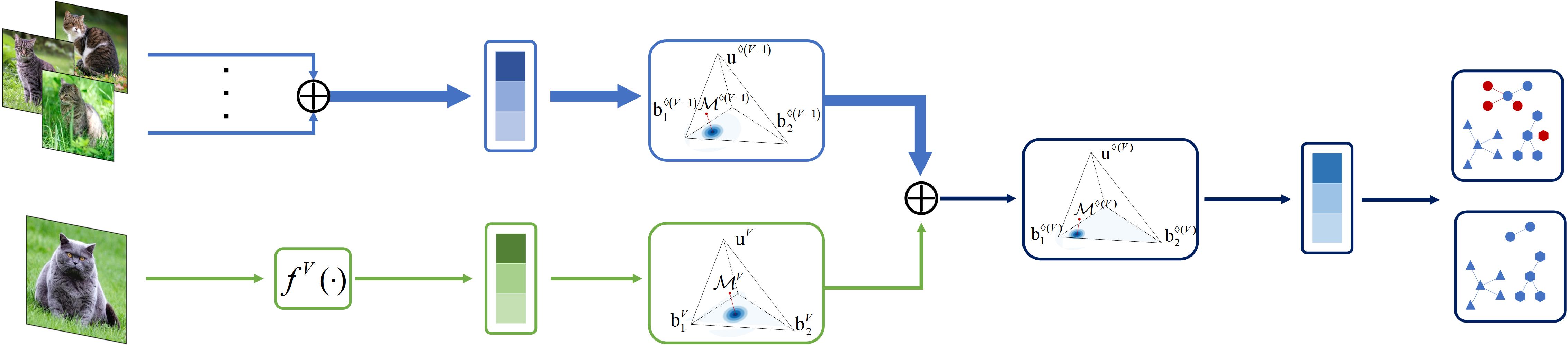 |
With the rapid advancement of multimodal data processing and the widespread adoption of large-scale foundation models, the complexity of integrating diverse data sources—such as text, images, audio, and sensor data—has significantly increased. However, challenges such as information conflicts, noise interference, and vulnerabilities to adversarial attacks pose substantial risks to the reliability and security of multimodal systems. These issues are particularly pronounced in safety-critical applications, where untrustworthy predictions can lead to severe consequences. The research team focuses on trustworthy multimodality (multi-view) learning to address these challenges. On one hand, considering that trustworthy multimodal learning inherently involves robust and reliable data fusion, the team develops methods for uncertainty-aware modality integration and dynamic confidence estimation, enabling accurate identification of conflicting or noisy data and enhancing decision-making reliability. On the other hand, the team incorporates explainability and privacy-preserving techniques to ensure fair and secure multimodal analysis, mitigating biases and safeguarding sensitive information. By combining these approaches, the team aims to establish a robust and trustworthy multimodal learning framework that supports reliable, safe, and interpretable decision-making across diverse real-world scenarios.
Topic 2: Lightweight Large Language Models
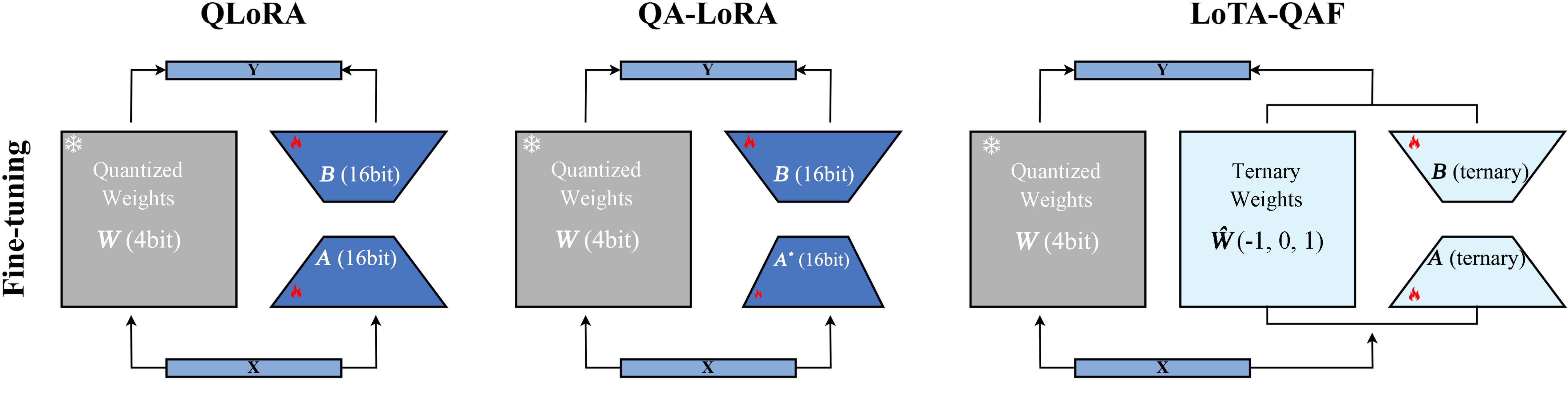 |
Lightweight Large Language Models (LLMs) are compact, efficient models designed to deliver high-performance natural language processing with minimal computational resources, enabling deployment on resource-constrained environments such as edge devices and mobile platforms. These models encompass techniques like model pruning, knowledge distillation, and low-bit quantization. Our research team focuses on advancing lightweight LLMs in resource-sensitive scenarios, with a particular emphasis on quantization techniques to optimize model size and inference efficiency.
Topic 3: Federated Learning
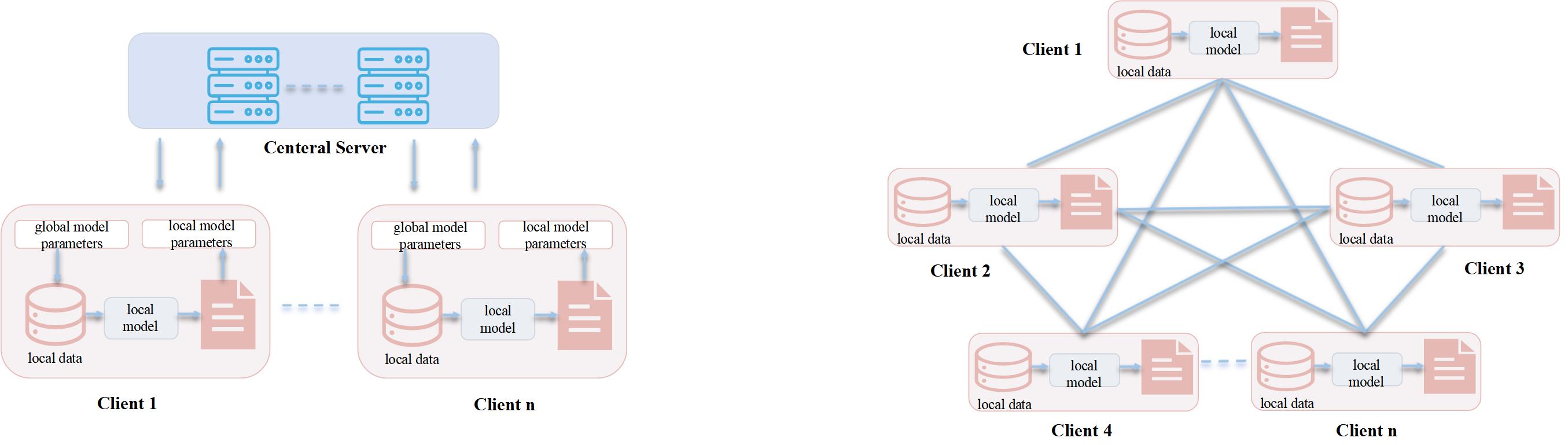 |
Federated Learning (FL) facilitates collaborative model training across decentralized devices while preserving data privacy, without centralizing raw data. However, heterogeneous data introduces key research challenges, such as statistical heterogeneity (non-IID distributions), model heterogeneity (varying architectures), and communication constraints, leading to performance degradation, fairness issues, and efficiency bottlenecks. In federated large models, these problems exacerbate during fine-tuning and deployment on resource-constrained edges, including data type mismatches and accuracy loss in quantization. Our research addresses these through adaptive optimization, lossless merging techniques, and edge-cloud frameworks for robust, scalable FL applications.